fishou
-
Compteur de contenus
9 -
Inscription
-
Dernière visite
Type de contenu
Profils
Forums
Téléchargements
Blogs
Boutique
Calendrier
Noctua
Tout ce qui a été posté par fishou
-
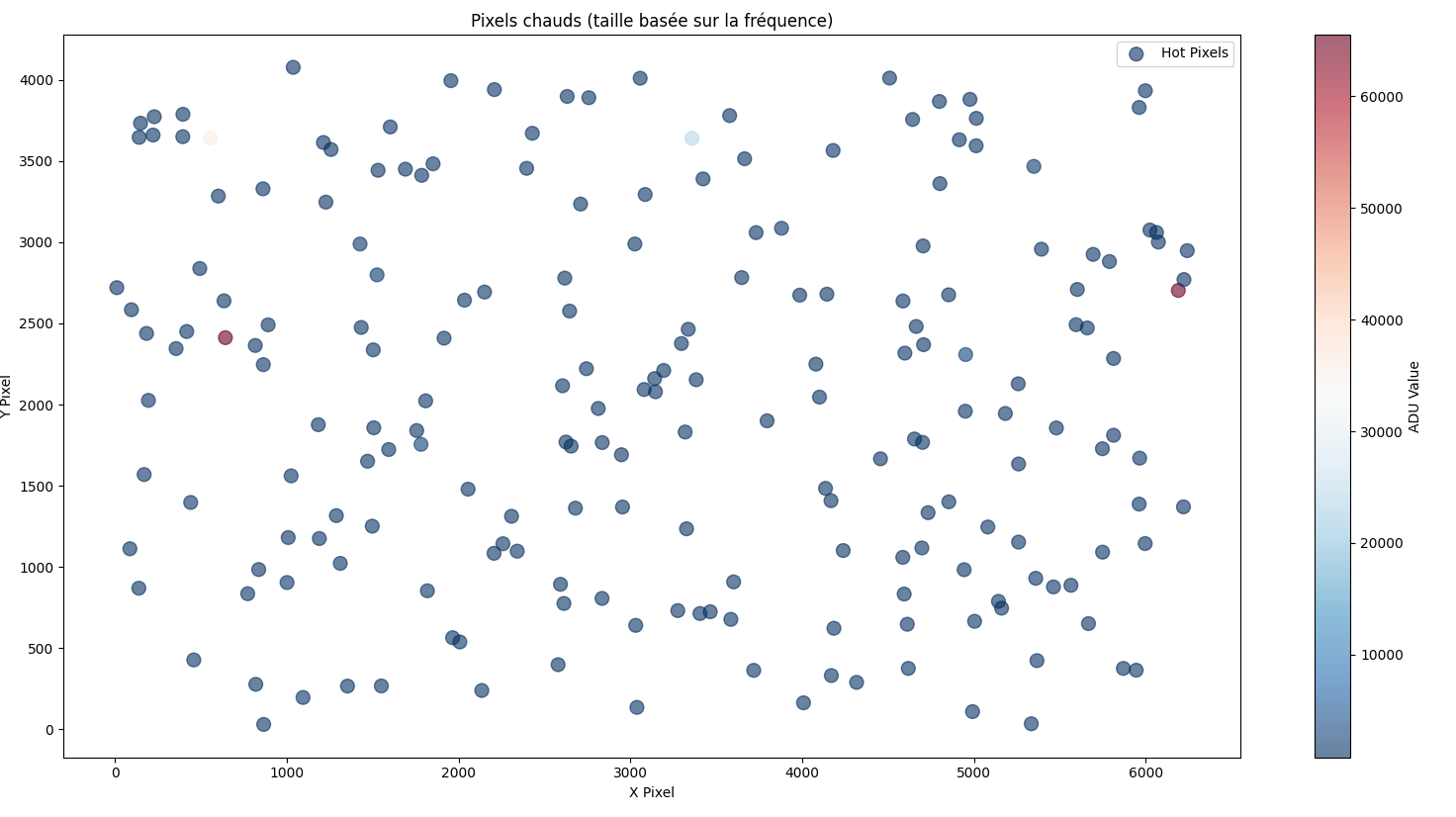
ZWO ASI 2600MC Pro - Pixels chauds
fishou a répondu à un sujet de fishou dans Matériel astrophotographique
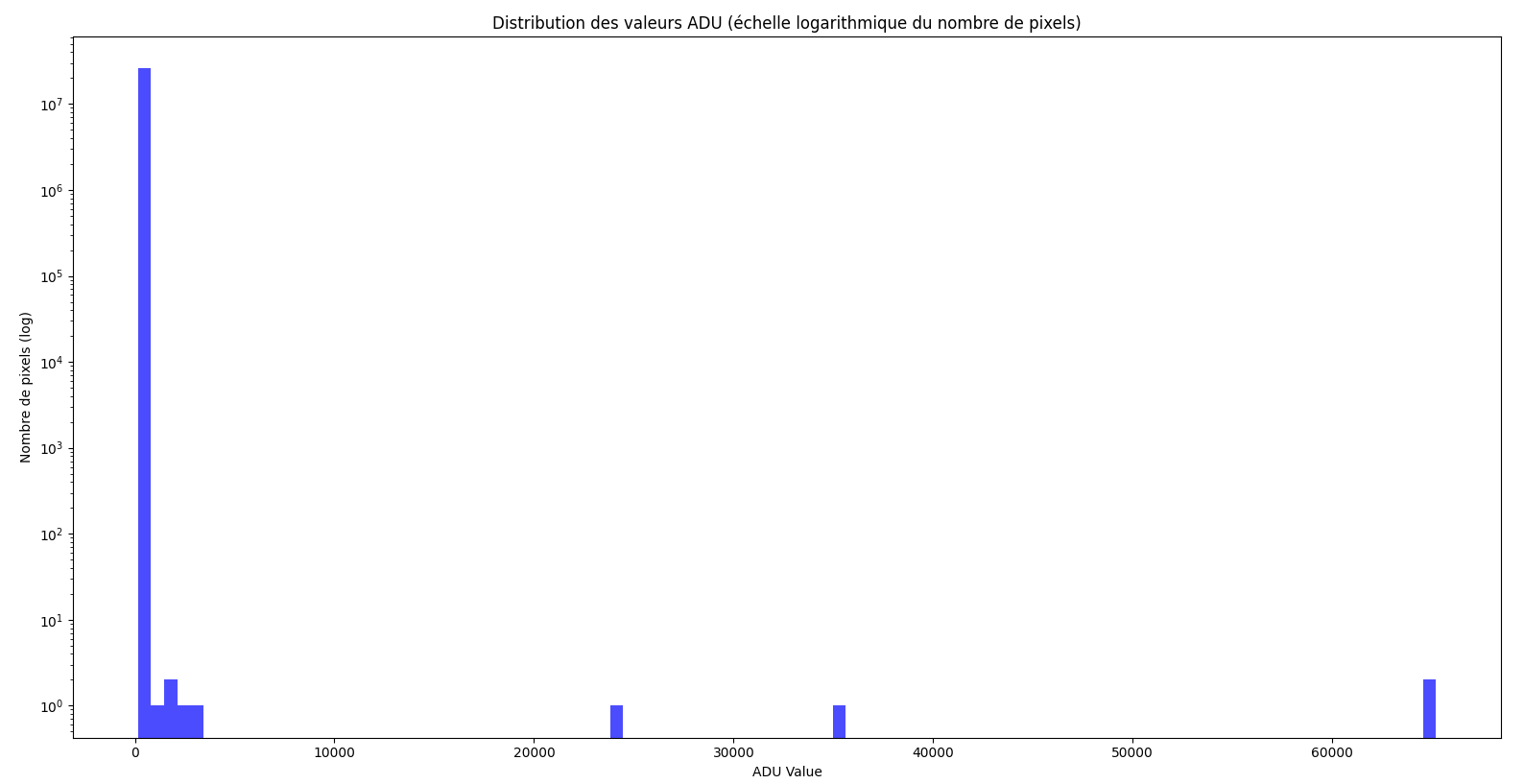
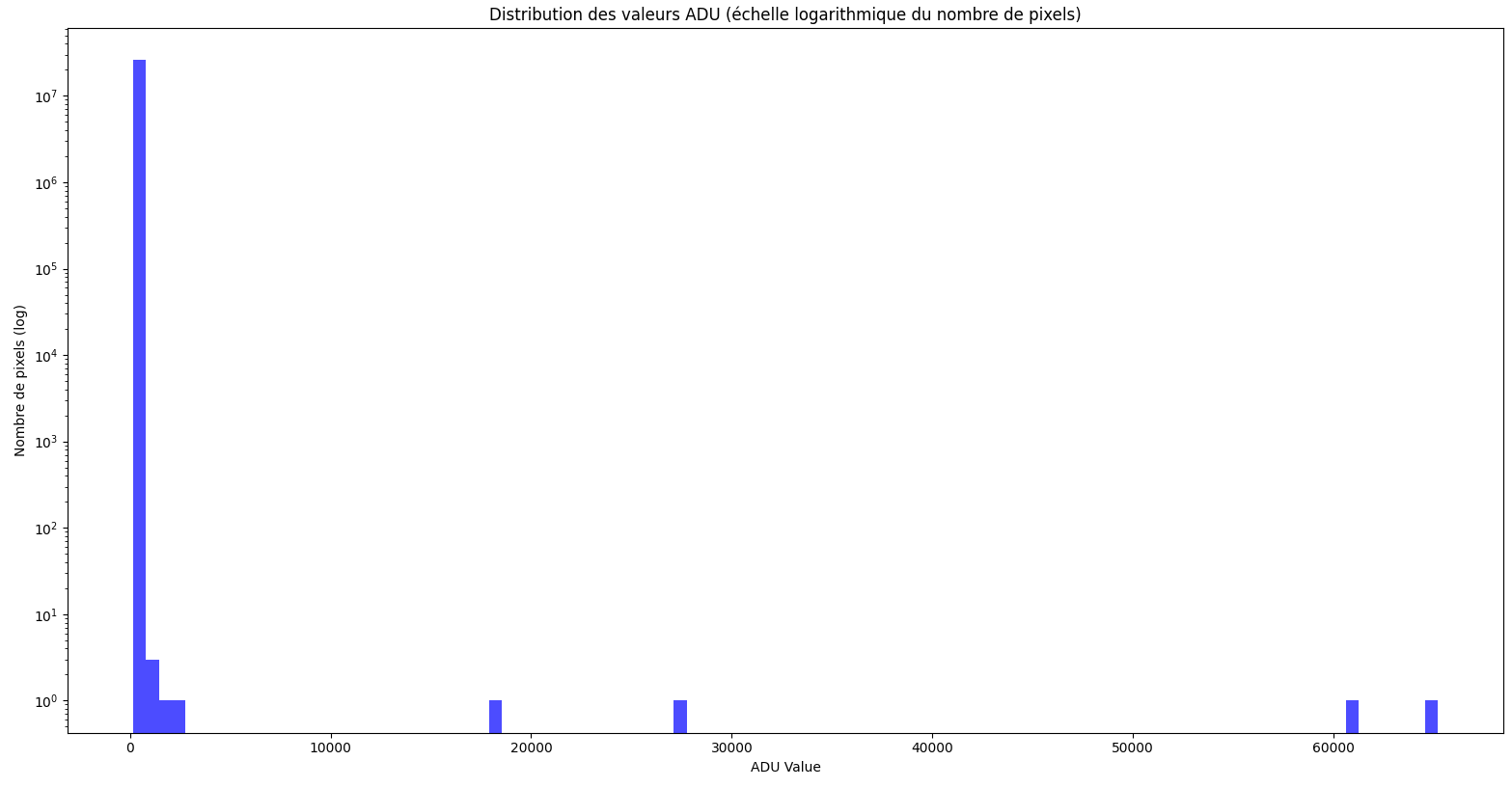
C'est un programme python que j'ai réalisé (avec l'aide de chatgpt, je ne suis pas un cador de la programmation). Si ça intéresse, je le mets là: from astropy.io import fits import numpy as np import matplotlib.pyplot as plt import pandas as pd import tkinter as tk from tkinter import filedialog import os from collections import Counter # Pour compter la fréquence des pixels chauds # Sélection dynamique du dossier contenant les fichiers FITS root = tk.Tk() root.withdraw() folder_path = filedialog.askdirectory(title="Sélectionnez un dossier contenant des fichiers FITS") if not folder_path: print("Aucun dossier sélectionné. Fin du programme.") exit() # Initialisation des variables pour la moyenne des données all_data = [] # Traitement de tous les fichiers FITS dans le dossier for file_name in os.listdir(folder_path): if file_name.endswith(('.fit', '.fits')): file_path = os.path.join(folder_path, file_name) print(f"Chargement du fichier: {file_path}") # Charger le fichier FITS hdulist = fits.open(file_path) data = hdulist[0].data hdulist.close() # Vérifier les dimensions des données if data.ndim != 2: print(f"Le fichier {file_name} n'est pas une image 2D valide. Ignoré.") continue # Ajouter les données à la liste all_data.append(data) # Vérifier s'il y a des images dans le dossier if not all_data: print("Aucune image valide trouvée dans le dossier.") exit() # Convertir la liste des images en un tableau NumPy ==> Chaque pixel = 1 valeur ADU all_data = np.array(all_data) # Calculer la moyenne de toutes les images ==> Chaque pixel est la moyenne d'ADU de toutes les images mean_image = np.mean(all_data, axis=0) # Statistiques de base pour la moyenne de toutes les images data_mean = np.mean(mean_image) data_median = np.median(mean_image) data_std = np.std(mean_image) print(f"Mean: {data_mean}, Median: {data_median}, Std Dev: {data_std}") # Histogramme des valeurs ADU avec une échelle logarithmique pour le nombre de pixels plt.figure() bins = np.linspace(mean_image.min(), mean_image.max(), 100) hist, edges = np.histogram(mean_image.flatten(), bins=bins) plt.bar(edges[:-1], hist, width=np.diff(edges), color='blue', alpha=0.7) plt.yscale('log') plt.title('Distribution des valeurs ADU (échelle logarithmique du nombre de pixels)') plt.xlabel('ADU Value') plt.ylabel('Nombre de pixels (log)') plt.show() # Détection des pixels chauds (avec la moyenne des images) threshold = data_mean + 15 * data_std # Seuil pour les pixels chauds hot_pixels = np.argwhere(mean_image > threshold) print(f"Nombre de pixels chauds (valeurs > {threshold} ADU) : {len(hot_pixels)}") # Extraction des 20 pixels les plus chauds flat_data = mean_image.flatten() sorted_indices = np.argsort(flat_data)[::-1] top_20_pixels = sorted_indices[:20] top_20_pixel_coords = np.unravel_index(top_20_pixels, mean_image.shape) top_20_values = flat_data[top_20_pixels] # Création d'un tableau des 20 pixels les plus chauds top_20_table = pd.DataFrame({ 'Pixel (Y, X)': list(zip(*top_20_pixel_coords)), 'ADU Value': top_20_values }) print("\nTop 20 Hot Pixels (highest ADU values):") print(top_20_table) # Sauvegarde des pixels chauds dans un fichier CSV hot_pixels_table = pd.DataFrame({ 'Y': hot_pixels[:, 0], 'X': hot_pixels[:, 1], 'ADU Value': mean_image[hot_pixels[:, 0], hot_pixels[:, 1]] }) hot_pixels_table.to_csv('hot_pixels.csv', index=False) print("\nListe des pixels chauds enregistrée dans 'hot_pixels.csv'.") # Compter la fréquence d'apparition des pixels chauds (nouvelle fonctionnalité) hot_pixels_list = list(zip(hot_pixels[:, 0], hot_pixels[:, 1])) hot_pixel_counts = Counter(hot_pixels_list) # Fréquences des pixels chauds # Extraire les coordonnées et les fréquences hot_pixel_coords = np.array(list(hot_pixel_counts.keys())) hot_pixel_frequencies = np.array(list(hot_pixel_counts.values())) # Visualisation des pixels chauds avec taille proportionnelle à leur fréquence plt.figure(figsize=(mean_image.shape[1] / plt.rcParams['figure.dpi'], mean_image.shape[0] / plt.rcParams['figure.dpi'])) plt.scatter( hot_pixel_coords[:, 1], # Coordonnées X hot_pixel_coords[:, 0], # Coordonnées Y s=hot_pixel_frequencies * 100, # Taille proportionnelle à la fréquence (facteur ajustable) c=mean_image[hot_pixel_coords[:, 0], hot_pixel_coords[:, 1]], # Couleur basée sur la valeur ADU cmap='RdBu_r', alpha=0.6, label='Hot Pixels' ) plt.colorbar(label='ADU Value') plt.legend() plt.title('Pixels chauds (taille basée sur la fréquence)') plt.xlabel('X Pixel') plt.ylabel('Y Pixel') plt.show() # Détection des pixels morts (avec la moyenne des images) dead_threshold = 100 # Seuil pour les pixels morts dead_pixels = np.argwhere(mean_image < dead_threshold) print(f"Nombre de pixels morts (valeurs < {dead_threshold} ADU) : {len(dead_pixels)}") # Visualisation des pixels morts avec échelle de couleur plt.figure(figsize=(mean_image.shape[1] / 100, mean_image.shape[0] / 100)) plt.scatter(dead_pixels[:, 1], dead_pixels[:, 0], s=10, c=mean_image[dead_pixels[:, 0], dead_pixels[:, 1]], cmap='cool', label='Dead Pixels', alpha=0.6) plt.colorbar(label='ADU Value') plt.legend() plt.title('Pixels morts sur l\'image moyenne') plt.xlabel('X Pixel') plt.ylabel('Y Pixel') plt.show() Ca permet de faire: L'histogramme des fréquences ADU moyennées Un tableau des 20 plus hautes valeurs ADU associées aux coordonnées Une représentation de la population des pixels chauds sur l'image moyennée De même pour les pixels mort (je n'en ai pas 🙂) Le code est perfectible mais ça fonctionnait pour ce que je voulais faire.
-
ZWO ASI 2600MC Pro - Pixels chauds
fishou a répondu à un sujet de fishou dans Matériel astrophotographique
Bien noté! Me voilà rassuré, merci à tous pour vos retours 🙂 -
Bonjour à tous, Je viens d'acquérir une caméra ZWO ASI 2600MC Pro et après analyse des premiers darks réalisés (en attendant un ciel sans nuage), j'ai pu détecter quelques pixels chauds et notamment certains qui saturent à 65535ADU lors des longues exposition. Pour l'analyse ci-dessous, j'ai moyenné les images avec 70darks dans les conditions décrites: Gain 100 / -10°C / 200s Statistiques valeurs ADU: Mean: 503.8, Median: 503.6, Std Dev: 20.3 Gain 100 / -10°C / 150s Statistiques valeurs ADU: Mean: 503.4, Median: 503.2, Std Dev: 18.9 Les positions des pixels chauds sont évidemment les mêmes selon les temps d'expo: 200s: Pixel (Y, X) ADU Value 0 (2412, 642) 65535.000000 1 (2703, 6190) 65535.000000 2 (3641, 555) 35595.028571 3 (3640, 3359) 24240.485714 4 (2308, 4952) 3331.357143 5 (1755, 1781) 2715.157143 6 (3467, 5349) 1951.071429 7 (2799, 1525) 1840.614286 8 (2989, 1426) 1660.457143 150s: Pixel (Y, X) ADU Value 0 (2412, 642) 61440.800000 1 (2703, 6190) 65535.000000 2 (3641, 555) 27664.614286 3 (3640, 3359) 18258.585714 4 (2308, 4952) 2704.457143 5 (1755, 1781) 2148.414286 6 (3467, 5349) 1586.028571 7 (2799, 1525) 1511.328571 8 (2989, 1426) 1369.871429 Les moyennes et écarts types me paraissent très correctes mais est-ce normal, pour ce capteur, d'avoir ces pixels chauds? Ca m'embête un peu, pour le prix, de savoir que j'aurais quelques pixels saturés. Mais c'est peut-être normal avec ces capteurs? Merci!